Probability and distributions
By the end of this module you will be able to:
- Explain normal distributions and what they tell you about data
- Describe correlation vs causation with examples
- Interpret basic statistical measures correctly
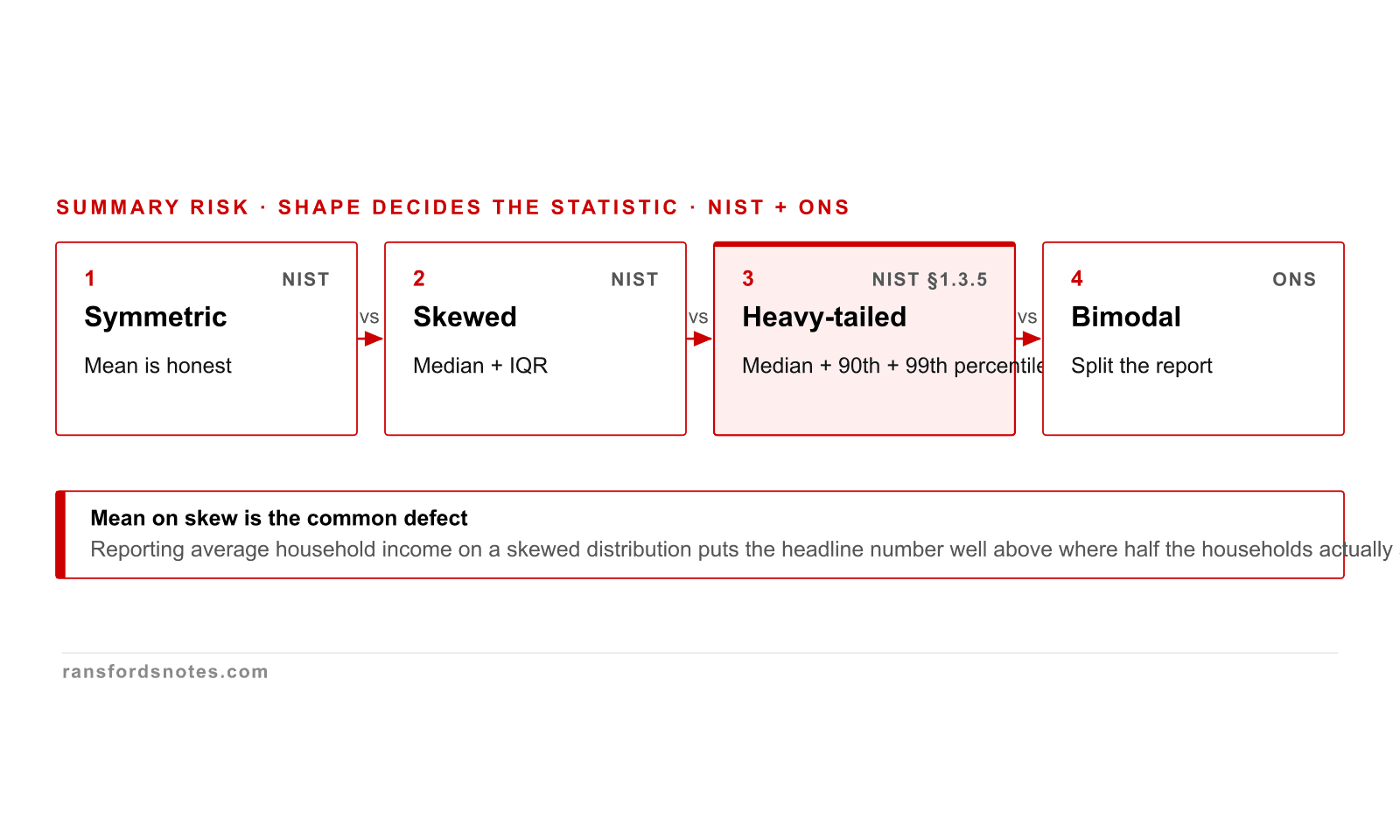
Distribution shape decides which summary statistic is honest
The honest summary statistic depends on distribution shape: symmetric, skewed, heavy-tailed, or bimodal.
The honest summary statistic depends on the distribution shape. Symmetric: mean. Skewed: median. Heavy-tailed: median plus percentiles. Bimodal: split the report. Picking the wrong summary distorts the claim; the NIST Engineering Statistics Handbook §1.3.5 lays this out.
Outlier decision path: identify, classify, handle by cause
An outlier is not a defect by default; classify the cause before handling it.
An outlier is not a defect by default. The decision path is: identify candidates, classify cause (measurement error, data-entry error, or genuine extreme), handle by the cause. NIST Engineering Statistics Handbook §7.1.6 sets the same shape; deleting genuine extremes loses the signal.
Choosing a summary statistic from audience and decision
Summary selection follows audience and decision, not the spreadsheet default.
Summary selection is a triage by audience and decision: what is the reader doing with the number? Reporting a typical value? Median. Detecting extremes? Percentiles. Comparing groups? Difference plus interval. The ASA 2016 statement makes the same point in reverse: do not pick a statistic that hides what the decision needs.
Real-world mistake · 2020
A council used average income to plan services. Half the residents were below it.
A London borough used mean household income to set eligibility thresholds for subsidised services. The mean was £38,000 per year. But the distribution was heavily right-skewed: most households earned between £20,000 and £30,000, while a small number of households in one ward earned over £200,000.
The median (£27,000) better represented the typical household. Using the mean excluded thousands of genuinely low-income households from support. Understanding distributions is not abstract mathematics; it determines who gets help.
The mean income in the area was £38,000. But the distribution was right-skewed: a few high earners pulled the average up. The median was £27,000. Which number should planners use?
Statistics is how we extract meaning from numbers. But statistical measures can mislead when applied without understanding the shape of the data. At this point in the path, the goal is practical judgement: when to trust a mean, a distribution, or a correlation. The formal mathematics of vectors, Bayes, entropy, and optimisation comes later in Data Practice and Strategy.
The first judgement is whether the data shape supports the statistic being reported.
16.1 Distributions and shape
A distribution describes how values in a dataset are spread. The shape tells you which summary statistics are reliable. For a normal, bell-shaped distribution, the mean, median, and mode are close together. For a skewed distribution, the median usually gives a better answer to "what is typical?" because a small number of extreme values can pull the mean away from most observations.
The normal distribution is useful, but it is an assumption to test, not a default to believe. The 68-95-99.7 rule applies only when the data is approximately normal: about 68% of values sit within one standard deviation of the mean, 95% within two, and 99.7% within three. Income, claims, house prices, outages, and incident duration often have long tails where that rule is unsafe.
A worked example: if incident duration has a mean of 62 minutes and a median of 18 minutes, the mean is telling you about operational exposure, while the median is telling you about a typical incident. A leader needs both numbers. The median describes the usual user experience. The mean warns that rare, severe events dominate total loss.
“All models are wrong, but some are useful.”
George Box, 'Science and Statistics' (1976) - Model criticism
Box's observation applies directly to distributions. A normal distribution is a model. Real data is never perfectly normal. The question is whether the normal approximation is useful enough for the decisions you need to make.
Common misconception
“The average is always the best summary of a dataset.”
The mean is pulled toward extreme values. In right-skewed data (income, house prices, insurance claims), the mean overstates the typical value. The median (the middle value when data is sorted) is strong to outliers. Always check the distribution shape before choosing a summary statistic.
Once the shape is visible, the next risk is mistaking association for cause.
16.2 Correlation versus causation
Correlation measures the strength and direction of a relationship between two variables. The Pearson correlation coefficient, written as r, ranges from -1 for a perfect negative linear relationship, through 0 for no linear relationship, to +1 for a perfect positive linear relationship.
Correlation does not establish cause. Ice cream sales and drowning rates rise together in hot weather because temperature affects both. A model that treats ice cream as the cause would give the wrong intervention. The right intervention is water safety, supervision, and heat-risk planning.
The technical test is not "are the variables moving together?" It is "what alternative explanation could make them move together?" Confounding, reverse causation, selection bias, seasonality, and measurement change all need to be ruled out before a correlation becomes decision evidence.
For executive decisions, the practical rule is simple: correlation is a signal for investigation, not permission to act. Establishing causation requires a controlled experiment, a credible natural experiment, or an observational design with explicit assumptions about confounders.
“Association does NOT imply causality.”
NIST/SEMATECH e-Handbook of Statistical Methods - Scatter Plot, Causality is not proved by association
NIST's warning is the operational rule for data leaders. A scatter plot or coefficient can reveal association, but the causal claim still depends on design, mechanism, and domain evidence.
Common misconception
“A correlation of 0.95 means one variable causes the other.”
A correlation of 0.95 means there is a strong linear relationship. But the relationship may be driven by a confounding variable (temperature drives both ice cream sales and drowning rates), reverse causation (revenue causes marketing spend increases, not vice versa), or coincidence (spurious correlations). Causation requires a plausible mechanism and controlled evidence.
A dataset of house prices in London has a mean of £620,000 and a median of £415,000. What does this tell you about the distribution?
A study finds a correlation of r = 0.87 between a country's chocolate consumption per capita and the number of Nobel laureates it has produced. What can you conclude?
A manager says: '95% of our customers are satisfied because the average satisfaction score is 4.2 out of 5.' What statistical error is this?
A marketing team reports that ice cream sales and drowning incidents are strongly positively correlated (r = 0.87). They conclude that ice cream causes drowning. What statistical fallacy is this?
Statistical checks to carry forward
- Distribution shape determines which summary statistics are reliable. For skewed data, the median often describes the typical case better than the mean.
- The 68-95-99.7 rule applies only when the data is approximately normal. Long-tailed operational and financial data needs percentile and tail-risk checks.
- Correlation measures relationship strength, but it does not establish cause. Confounders, reverse causation, selection bias, and seasonality must be tested before action.
- A single average can hide the decision-critical pattern. Report the distribution, the spread, the median, the tail, and the sample size before drawing conclusions.
Standards and sources cited in this module
Box, G.E.P. (1976). 'Science and Statistics'
Model criticism
Source for 'all models are wrong, but some are useful.' Applied to distribution assumptions throughout this module.
NIST/SEMATECH e-Handbook of Statistical Methods
Normal Distribution and Scatter Plot sections
Primary teaching source for normal-distribution assumptions, correlation, and the warning that association does not prove causality.
Full article
Famous spurious correlation demonstration. Used as the quiz example of correlation vs causation.
Tukey, J.W. (1977). Exploratory Data Analysis
Chapters 1-3
Foundational text on examining distributions before computing statistics. Introduced the box plot and emphasised data shape.
Data Science and Analytics knowledge area
Industry framework for statistical analysis capability within data management.
Module 16 of 26 · Applied Data