Architectures and pipelines
By the end of this module you will be able to:
- Distinguish ETL from ELT and explain when each is appropriate
- Compare batch and streaming processing for a given latency requirement
- Describe the key architectural difference between a data warehouse and a data lake
- Identify the role of each component in a modern data stack
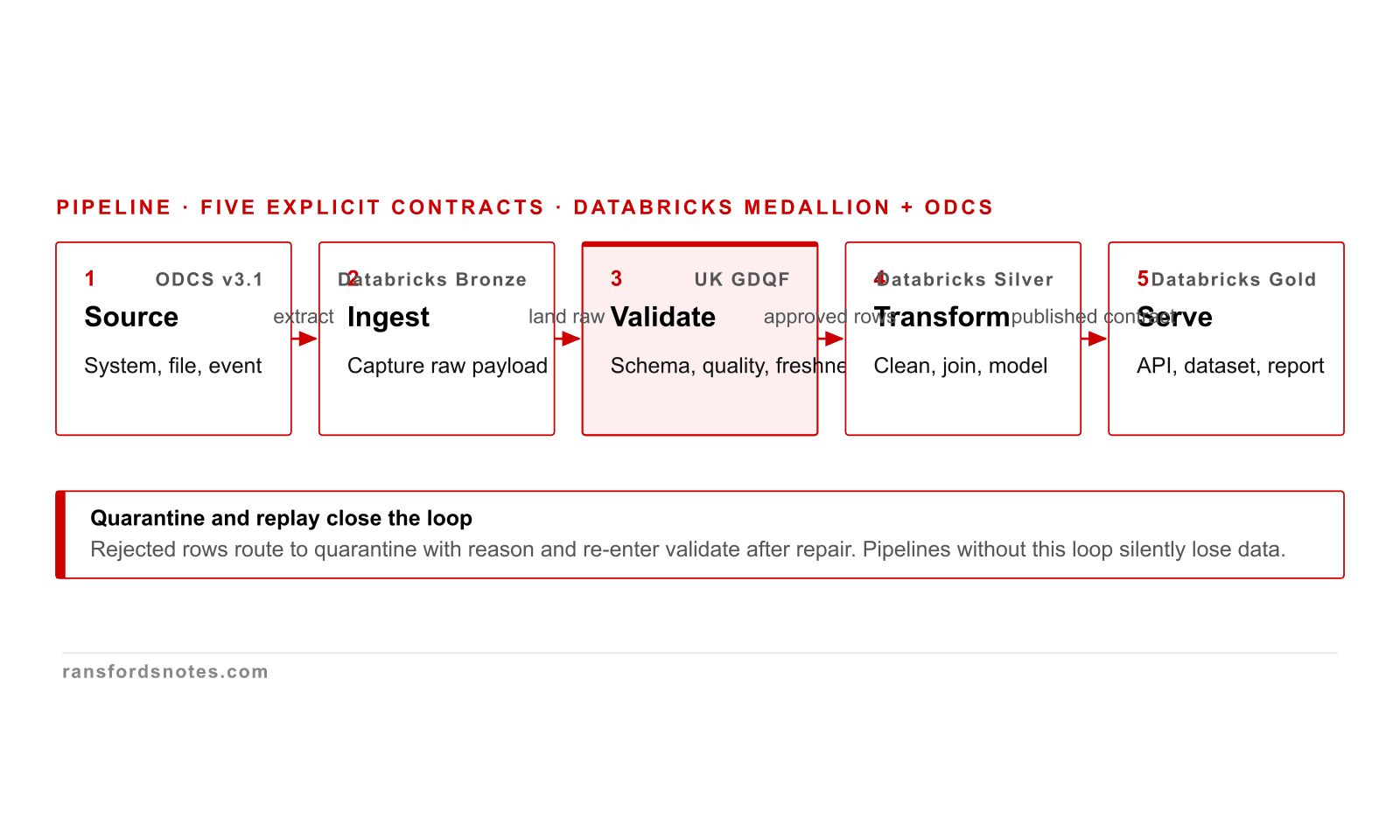
Pipeline as a chain of contracts from source to serve
A pipeline is a chain of explicit contracts from source through validate to serve, with quarantine and replay as a closed loop.
A pipeline is a chain of explicit contracts, not a flat sequence of scripts. Source, ingest, validate, transform, serve each carry their own contract; failures route to quarantine and replay back into validate. Databricks medallion architecture names the same five-step shape.
Medallion architecture promotion gates between layers
Medallion architecture moves data Bronze to Silver to Gold with explicit promotion gates between layers.
Medallion architecture moves data through Bronze (raw, immutable), Silver (cleaned, deduplicated, schema-enforced), and Gold (business-ready, aggregated). The promotion gate between each layer is a named quality check; without it, the layers collapse into one bag of files. Databricks documents the same shape.
Four named pipeline failure modes with four actions
Pipeline failures have four named modes with four different actions; naming the mode turns alerts into actions.
Pipeline failures have four named modes: schema drift, quality miss, freshness miss, and downstream contract break. Each has a different action: reject + alert, hold + repair, refresh, notify consumer. Naming the mode turns vague pipeline-broken alerts into specific actions.
Real-world scale · ongoing
Netflix processes 500 billion events per day. Not all of them need the same speed.
Netflix processes over 500 billion events per day from user interactions: plays, pauses, searches, ratings, and scroll behaviour. Billing aggregations run as nightly batch jobs. Recommendation updates run in near-real-time through Apache Kafka streams.
The architecture choice determines what is possible. The Foundations stage covered what data is and how it is governed. This module opens the Applied stage by examining how data moves through systems at scale.
Billing aggregations can wait hours. But when a user finishes an episode, the next recommendation must appear in seconds. How does architecture make both possible?
A data pipeline is a sequence of automated processes that moves data from source systems to a destination, applying transformations along the way. Every pipeline must answer three questions: where does the data come from, what processing is required, and where does it need to go?
The first architecture decision is where transformation should happen.
12.1 ETL versus ELT
ETL (Extract, Transform, Load) transforms data outside the destination in a separate processing layer, then loads clean data. ELT (Extract, Load, Transform) loads raw data first, then transforms inside the destination using its compute power.
ETL dominated when warehouse compute was expensive. ELT became more common because cloud warehouses like BigQuery, Snowflake, and Redshift offer elastic compute that makes in-warehouse transformation faster and cheaper than external processing. dbt (data build tool) is a widely used ELT transformation tool, using SQL models versioned in Git.
“Data architecture defines the blueprint for managing data assets by aligning with organisational strategy to establish strategic data requirements and designs to meet those requirements.”
DAMA-DMBOK2 (2017) - Chapter 4, Data Architecture
DAMA frames architecture as strategy-driven, not technology-driven. The choice between ETL and ELT, batch and streaming, warehouse and lakehouse all depend on what the organisation needs from its data, not on which technology is newest.
Common misconception
“ELT is always better than ETL because it uses the warehouse's compute.”
ELT is more efficient when the destination has elastic compute (cloud warehouses). But ETL remains appropriate when transformation requires external libraries (Python ML models, geospatial processing), when data must be cleansed before entering a regulated destination, or when the destination has limited compute capacity. The choice is architectural, not dogmatic.
The next decision is how fresh the data must be for the decision it supports.
12.2 Batch versus streaming
Batch processing collects data over a period (hourly, daily, weekly), then processes it all at once. Streaming processing handles data continuously as it arrives, event by event. The trade-off is latency versus complexity.
Batch is simpler, cheaper, and sufficient for many analytical workloads. Streaming is necessary when decisions depend on fresh data: fraud detection where seconds matter, recommendation engines where the next suggestion must appear before the user leaves, and operations centres monitoring live systems.
Apache Kafka is a widely deployed streaming platform. It handles event ingestion at millions of events per second. Apache Flink and Spark Structured Streaming process those events with transformations and aggregations.
“Processing real time streaming data requires throughput scalability, reliability, high availability, and low latency.”
AWS Well-Architected Framework, Data Analytics Lens - Streaming ingest and stream processing
AWS's guidance makes the trade-off explicit. Streaming is an operating capability with reliability, scalability, and latency obligations, not just a faster version of batch.
Storage architecture then decides what structure, governance, and engines the platform can support.
12.3 Warehouse, lake, and lakehouse
A data warehouse (Snowflake, BigQuery, Redshift) stores structured, schema-enforced data optimised for SQL analytics. It provides fast query performance but requires data to be modelled before loading.
A data lake(S3, Azure Data Lake, GCS) stores raw data in any format: structured, semi-structured, and unstructured. It provides flexibility but risks becoming a "data swamp" without governance, cataloguing, and quality controls.
A data lakehouse pattern (Databricks Lakehouse, Apache Iceberg, Delta Lake) combines both: open file formats stored in a lake with warehouse-like features (ACID transactions, schema enforcement, time-travel queries). The lakehouse pattern emerged around 2020 as a major modern architecture for organisations that need both analytical and machine learning workloads.
Common misconception
“A data lake is just a cheap data warehouse.”
A data lake stores raw, unstructured, and semi-structured data that a warehouse cannot handle (images, log files, sensor data, JSON documents). The key difference is schema enforcement: warehouses require schema-on-write (define the structure before loading), while lakes allow schema-on-read (interpret the structure when querying). A lakehouse adds warehouse-like governance to lake storage.
A fintech startup uses BigQuery as its data warehouse. Raw transaction data lands in BigQuery via Fivetran connectors. A data engineer writes SQL transformations in dbt to create analytics-ready tables. Which pipeline pattern is this?
A logistics company needs to calculate optimal delivery routes. Route calculations require Python geospatial libraries (not SQL). The results feed into an operational database. Should this use ETL or ELT?
A bank runs nightly batch pipelines for regulatory reporting. The CFO asks whether switching to streaming would improve report accuracy. What is the best response?
A retail company loads daily sales CSVs into a data warehouse using an ETL process. They want to add real-time inventory updates. Which architecture change is most appropriate?
Architecture checks to carry forward
- ETL transforms before loading. ELT loads first and transforms in the destination. The right choice depends on regulation, tooling, compute location, cost, and workload.
- Batch handles scheduled chunks. Streaming handles events as they arrive. Streaming needs reliability, availability, throughput, latency controls, and stronger operational discipline.
- Warehouses optimise governed SQL analytics. Lakes store varied raw data with schema-on-read. Lakehouse table formats add transactions, schema evolution, and time travel to lake storage.
- A production stack needs observability across ingestion, storage, transformation, serving, and quality. Monitoring is part of the architecture, not an afterthought.
- Architecture choices should start from latency, scale, cost, risk, and decision need. Technology trends are not requirements.
Standards and sources cited in this module
Data Architecture knowledge area
Defines data architecture as strategy-driven, not technology-driven. Provides the conceptual framework for pipeline and storage architecture decisions.
AWS Well-Architected Framework, Data Analytics Lens
Batch and streaming data processing
Industry guidance on batch processing, streaming processing, reliability, latency, and workload trade-offs.
Databricks, 'Lakehouse: A New Generation of Open Platforms' (2021)
Full paper
Academic paper introducing the lakehouse architecture combining lake storage flexibility with warehouse-like governance.
Project overview
Open table format reference for schema evolution, time travel, and reliability features in lakehouse-style architectures.
dbt Labs, 'What is dbt?' (2024)
Documentation
dbt is a widely used ELT transformation tool. Used in the terminal simulation and referenced throughout the ELT discussion.
Netflix Technology Blog, 'Evolution of the Netflix Data Pipeline' (2016)
Full post
Source for the 500 billion events/day figure and the batch/streaming architecture discussion in the opening case study.
Module 12 of 26 · Applied Data